

Table of contents


No headings in the article.
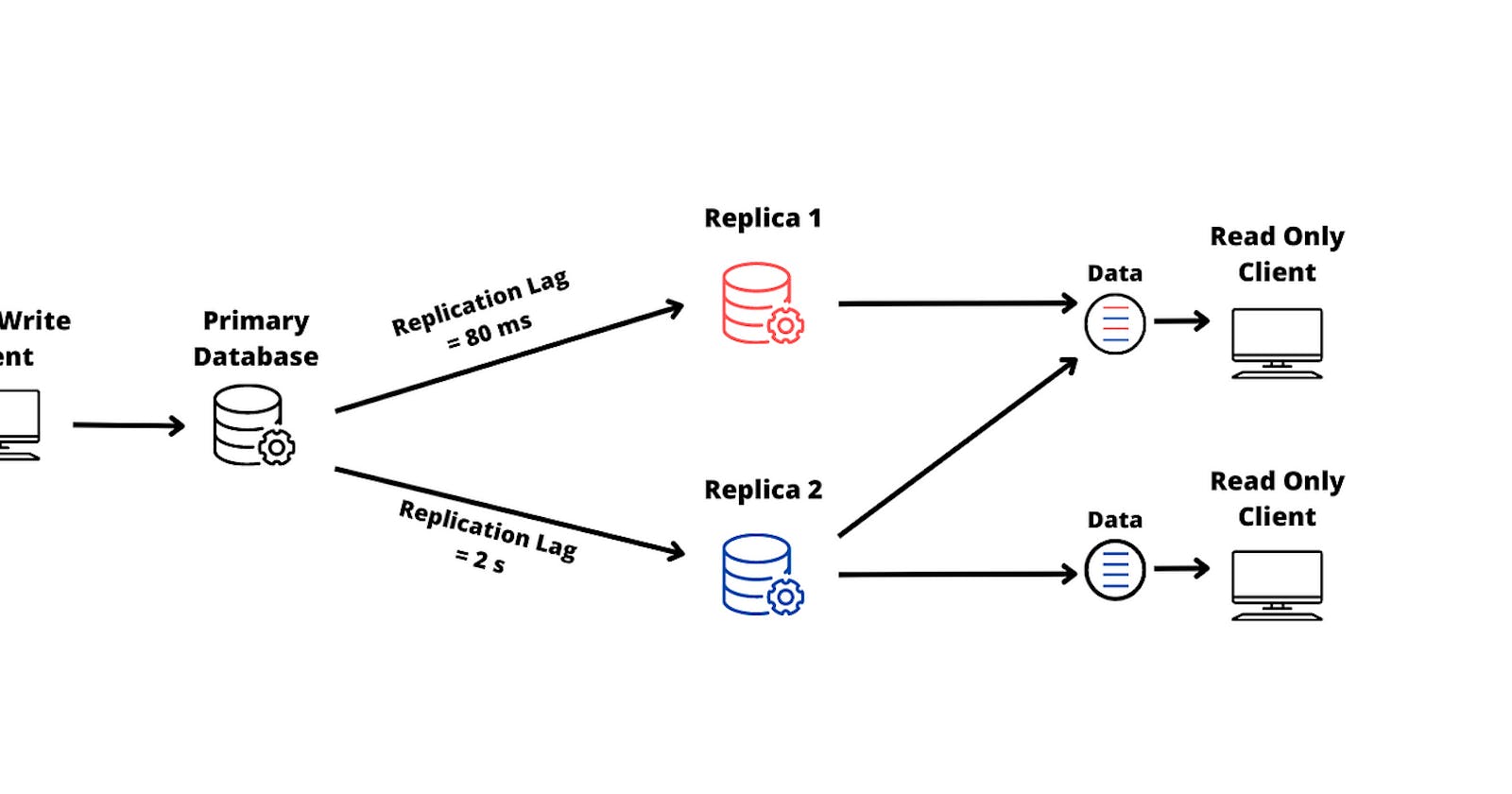
Replication lag is a common phenomenon in computing. In a leader-based replication setup, all writes usually go through a single node. On the other hand, all read-only queries can be served by any replica. In the long run, this is good as you can scale up the read operations by just adding more replicas.
However, to gain the full power of replication, asynchronous replication is the most plausible option. The only cons to this is the fact that the application might read outdated information from the replica if the replica has fallen behind for any reason.
Some of the reasons could be:
- User A sends an update (write) request to the primary or leader node, the leader node sends the replication information to its replicas. Replica 1 gets updated. User B then requests (reads) data from replica 2 and gets outdated information. Replica 2 then gets updated.
The delay between write happening on the leader and being reflected on a follower node is basically what replication lag means. In most cases, the lag might be a couple of seconds which might not be noticeable, however, if the system is operating on a limit, the lag can increase to several seconds or minutes
Database replication lag is frustrating to the end users. Assume that you are updating your social media profile and it takes several seconds after pressing save for the changes to reflect. That is a horrible experience.
How to fix the replication lag.
To fix replication lag, read-after consistency should be employed. Sometimes, this is referred to as read-your-writes-consistency. This offers a guarantee that if a user makes an update, they will see the updates when they view the information. This reassures the user that their input has been saved correctly even though replication might still be going on in the background.
How to implement this guarantee.
To implement read-after-write guarantee:
When reading any new information that the user has updated, read it from the leader. Otherwise, read it from the follower. This is ideal for cases such as profile information that can only be editable by the owner of the profile.
The client keeps track of the timestamp for the most recent write. The system ensures that the replica serving any reads for that user has the updates until that timestamp.
Monitor the replication lag on followers and prevent queries on any followers or replicas that are more than one or two minutes behind the leader.
Databases such as MongoDB and Object Storage(such as S3) have started providing read-after-write as an option.
That is it for today. Thank you for your time.
credits to @progressivecod2 on twitter.