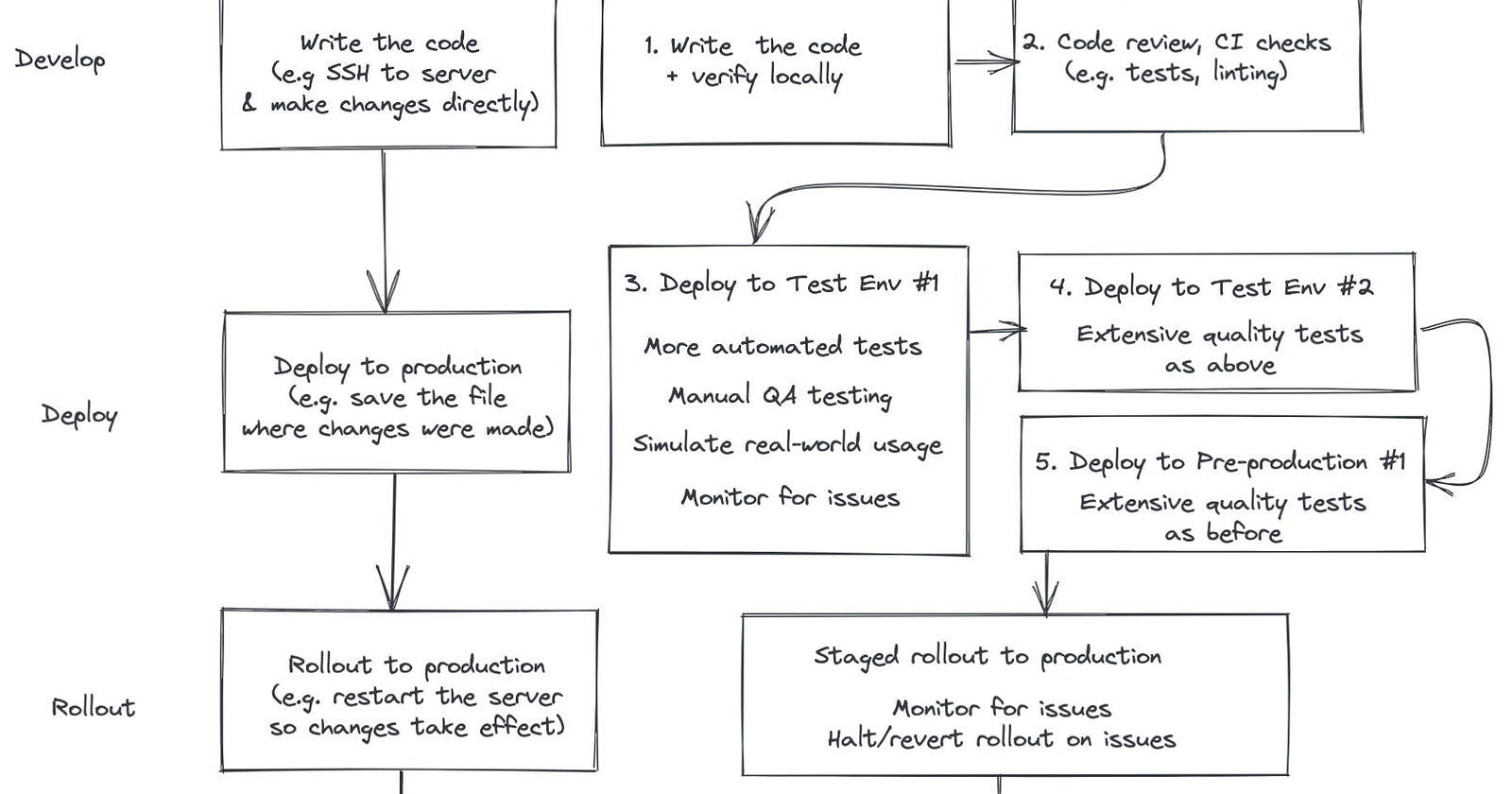


The process of shipping code to production is one of the core processes that every organization routinely engages in. It is therefore paramount that this process should be as strict as possible. The process should also pass through a series of checks, tests, stages, and dry runs. Below is a blueprint of what needs to be done. This is not an exclusive list as it depends on the organization, the teams in the organization, the size of the user base, and the tools and budget.
Product Owner creates Stories- The Product Owner creates stories based on the user's requirements.
Dev team picks the User Stories- The responsible team picks the user stories from the backlog and puts them into a Sprint for a two-week dev cycle.
Dev commits to Git- The developers in the team commit to the source code repository. This is mostly the git.
The build is triggered- A build is triggered in Jenkins. At this point, the Source code should have passed the Unit tests, code coverage thresholds, and gates such as in SonarQube.
The build is successful- If the build is successful, the build is stored in an artifact factory. The build is then deployed into the dev environment.
Independent testing- If multiple dev teams are working on different features, the features need to be tested independently, so they are deployed to QA1 and QA2.
Quality Assurance testing, Regression testing, Performance testing- The Quality Assurance team picks a new QA environment and performs the QA testing, Regression testing, and Performance testing.
Deployment to UAT environment- Once the QA builds pass the QA's team verification, they are deployed to the UAT(User Acceptance Testing) environment, where the QA team, dev team, and even the product owner perform UAT testing.
If UAT testing is successful, the builds become release candidates and will be deployed to the production environment on schedule. It is advisable not to deploy to all the users at a go to mitigate the change risks so some techniques like feature toggle, and Canary deployment can be used.
Site Reliability Engineer- The SRE team is responsible for prod monitoring. They leverage a bunch of log-analyzing tools and process-tracing tools like ELK Stack, Prometheus, and Skywalking. They report production issues to QA and dev teams, and teams need to fix them based on defined priority.
That is it for today. Thank you for your time.