How Services discover each other in MicroServices.


In a simple monolithic application, all services run in the same instance. Successful applications tend to grow over time and eventually become huge. Once the application has become huge, it becomes a monstrous monolith. Additionally, as the services grow, the load grows, and the team grows. With time, the monolithic application will slowly be transformed into a set of independent services. In other words, the monolithic application is transformed into a Microservices architecture.

With Microservices, comes the issue of service discovery. With multiple independent services in place, each running on its own set of instances. An instance might go down and a new instance added. So how will the instances identify each other?
There are two ways services discover each other:
Server-side discovery.
In this discovery, a load balancer is set up between two services. All service A instances know and use a single IP address(or domain name) of the Load balancer. The client sends a request to the LB(Load Balancer), and the LB forwards the requests to Service B instances.
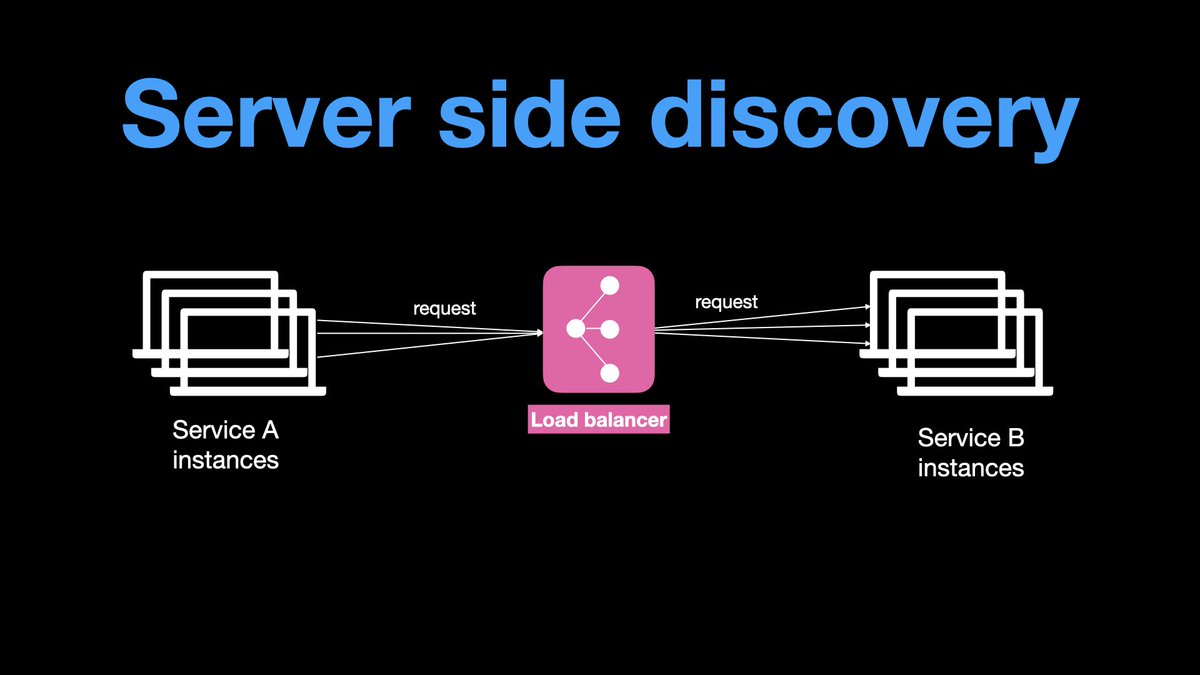
Load balancers are an interesting set of infrastructure that I will talk about soon.
Client-side discovery.
With all client-side discovery, all service B instances register themselves in a shared location, called service registry.
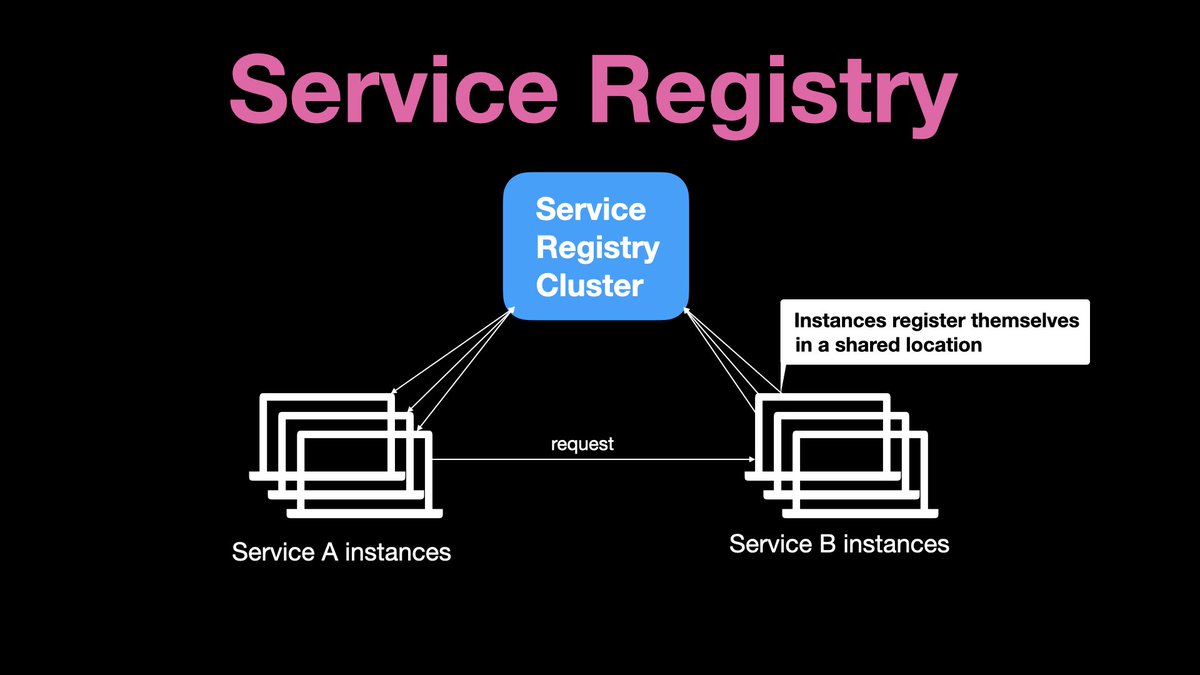
Every service A instance reads this information from the service registry, gets the list of all available service B instances and picks one in particular instance to send a request to it.
Data replication allows any service registry node to serve read requests. So when service A asks the service registry about service B, any server in the cluster can respond with the recent information about Service B instances.
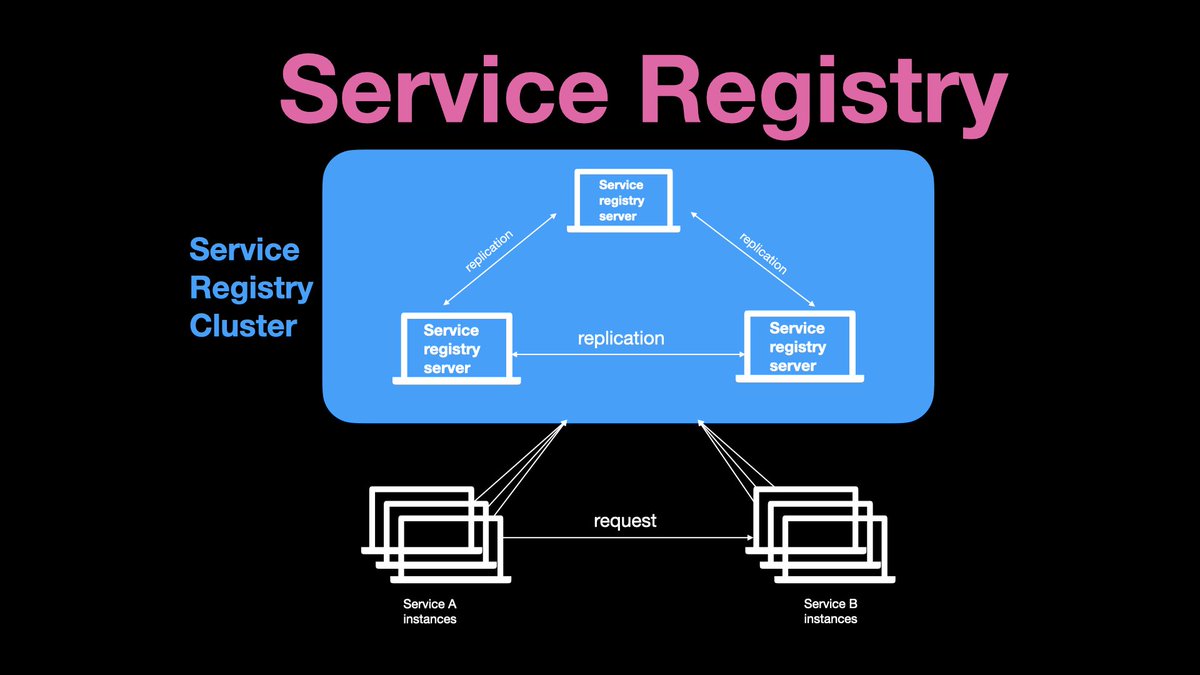
Important to note that service B instances need to constantly send heartbeat requests to the services registry. For example, every few seconds, to notify the registry that instances are alive.
When a new instance is added, it sends a request to the service registry with its IP address and port number. The service registry replicates this new instance information across the cluster instances.
It is important to note that sometimes, Service A instances may want to cache results coming from the services registry. Why? because the registry service itself may become unavailable. For instance, due to network failure.
So how do services retrieve information from the service registry? There are two options for how we can integrate services with the query API of the service registry.
Using service registry client.
Using service registry daemon process.
The most straightforward option is to implement a service registry client component and embed this client into the service application. The client knows how to talk to the service registry and how to cache the information returned from it.
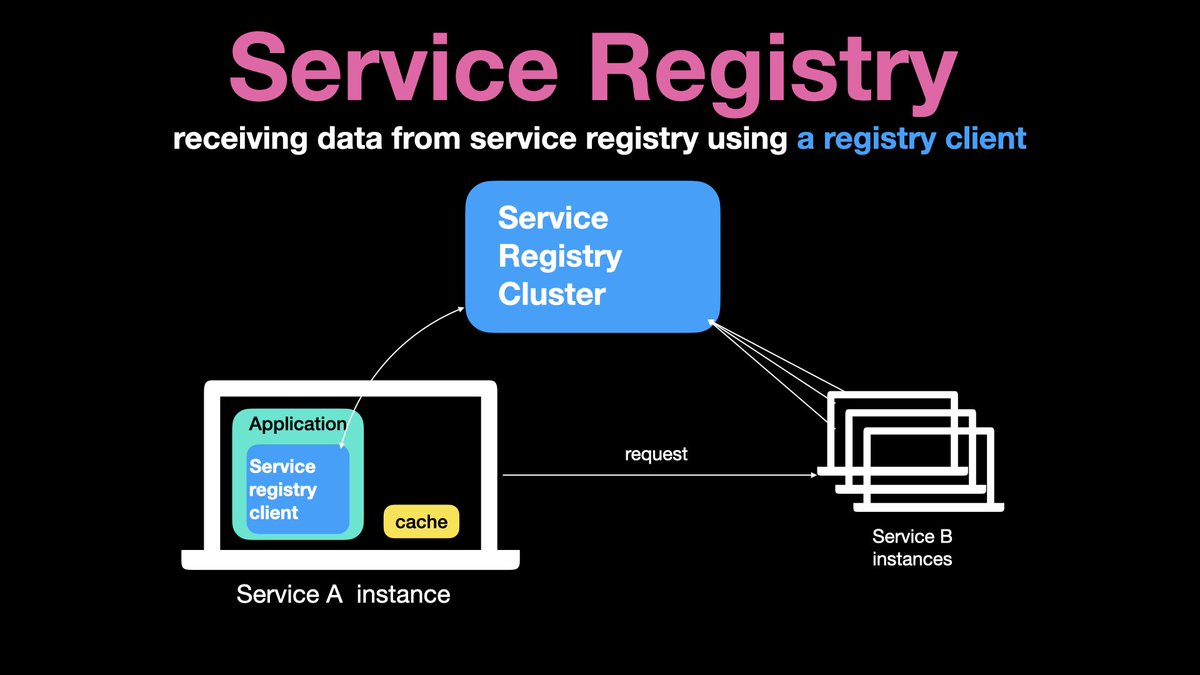
The main benefit of this approach is that it is easy to implement and maintain. But this pattern requires us to have clients written in different languages. For instance in Java, we will need a Java Client, for Python, we will need a Python client and so on.
A different approach is to decouple the application and the Service registry client by creating a separate daemon process. This process runs on every service A machine in the cluster. It is connected to the services registry, retrieves information from it and stores it locally.
We can further this and use the information to configure a Load balancer process running on the same machine. The application then sends requests to the Load balancer, and the Load balancer sends these requests out to service B instances. The daemon approach is programming language agnostic. This means that it doesn't have to be in the same language as the services application. Secondly, the approach is less error-prone. The daemon process uses its own memory space. If there are bugs introduced in the daemon application, the services application is not impacted. And when the daemon process experiences issues while talking to the services registry, all these faults are isolated to the daemon process only.
Thank you for your time and see you in the next.
Special credits to @happydecoder on X(Formerly Twitter).